For the a period of 18 months or so I slowly ported my chess by rss site (chrss) from Turbogears 1.0 to Django. When I started the port Django 1.1 was the latest version. I took so long to finish the port, that Django got to version 1 …
Articles tagged with Chrss
Turbogears, remember me
So a while back I implemented a remember me feature for chrss. I said I'd release the code for it and am finally now getting round to it.
Please note that this kind of "remember me" functionality can represent a potentially security hole. It makes sense for some sites where …
A turbogears caching decorator
A while back I wrote a caching decorator for chrss. It's mostly used for the rss feeds, to help avoid having over-zealous rss readers slowing the site down. However I'm also now running it on a few other pages that were a bit slow (notably generating PGN files for games …
chrss (chess by rss) update 22
chrss (chess by rss) update 21
Another update to chrss.
- tweaked front page layout to make it clearer and show different options depending on if you are logged in or not
- addition of a help section (with backend CMS for myself to add content to it).
At the moment the help section is not directly linked …
When developing in your spare time automated tests are your best friend
Well I just finished fixing a bug in chrss and it's made me very glad that I've been using automated tests.
The bug looked like it might be very tricky to track down and I feared that it might get messy. In the end it proved to be a slight …
chrss (chess by rss) update 20
- Updated the user registration process, so hopefully it's a bit friendlier
- Users now have a chance to resend their activation email if they have trouble activating their account
- Tweaked filters for games on user's page:
- "active" - games that it's your turn in or have had a move in the last …
Turbogears and mobile mini-site logins
I'm in the process of to writing a simple mobile version of chrss (chess by rss). This is spurred by the arrival of my new Nokia 6300 (which comes with Opera Mini). I'm aiming to end up with a mini-site running at http://chrss.co.uk/mob/ or similar.
The …
chrss (chess by rss) update 19
- Bug fix for PGN (Portable Game Notation) output (as noted by Calibius)
- Faster PGN generation (evaluating only the legal moves I need to consider to avoid ambiguity, rather than _all_ legal moves)
- URLs in comments should now automatically appear as click-able links
- Ability to "rotate" the board, to view it …
chrss (chess by rss) update 18
simple bread crumbs added to aid navigation:

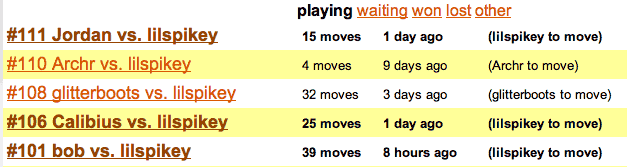
highlighting games that it's your turn to move in:
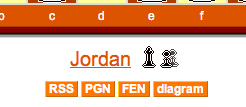
PGN (portable game notation) output for games:
improved test coverage